JAVA 大数据结构,技能选型与运用实践
时间:2024-12-27阅读数:14
1. Apache Hadoop:Hadoop 是一个分布式核算结构,它答运用户在低成本的硬件上运转大数据处理使命。Hadoop 由 HDFS(Hadoop Distributed File System)和 MapReduce 两个首要组件组成,别离用于数据存储和核算。
2. Apache Spark:Spark 是一个快速、通用的大数据处理引擎,它供给了比 Hadoop MapReduce 更高的核算速度和更丰厚的 API。Spark 支撑多种编程言语,包含 Java、Scala、Python 和 R。
3. Apache Flink:Flink 是一个流处理结构,它支撑批处理和流处理。Flink 供给了高吞吐量、低推迟和容错性,适用于实时数据处理和剖析。
4. Apache Kafka:Kafka 是一个分布式流处理渠道,它用于构建实时的数据管道和流运用程序。Kafka 支撑高吞吐量、可扩展性和容错性,适用于大规划数据处理。
5. Apache Hive:Hive 是一个数据仓库东西,它答运用户运用 SQL 句子查询和办理存储在 Hadoop 中的大数据。Hive 供给了相似联系型数据库的查询接口,简化了大数据处理和剖析。
6. Apache HBase:HBase 是一个分布式、可扩展的、面向列的存储体系,它构建在 Hadoop 文件体系之上。HBase 适用于需求随机、实时读写的运用场景,如实时监控和实时剖析。
7. Apache ZooKeeper:ZooKeeper 是一个分布式和谐服务,它用于保护装备信息、命名、供给分布式同步和组服务。ZooKeeper 在大数据结构中用于完成分布式体系的和谐和装备办理。
8. Apache Storm:Storm 是一个实时流处理结构,它答运用户在实时数据处理和剖析中快速构建和布置运用程序。Storm 供给了高吞吐量、容错性和可扩展性,适用于实时数据处理和剖析。
这些结构各有特色,适用于不同的运用场景。在挑选适宜的结构时,需求考虑数据规划、处理速度、容错性、可扩展性等要素。
深化解析Java大数据结构:技能选型与运用实践
跟着大数据年代的到来,Java作为一门老练且广泛运用的编程言语,在数据处理和剖析范畴扮演着重要人物。本文将深化解析Java大数据结构,讨论其技能选型与运用实践,协助读者更好地了解和运用这些结构。
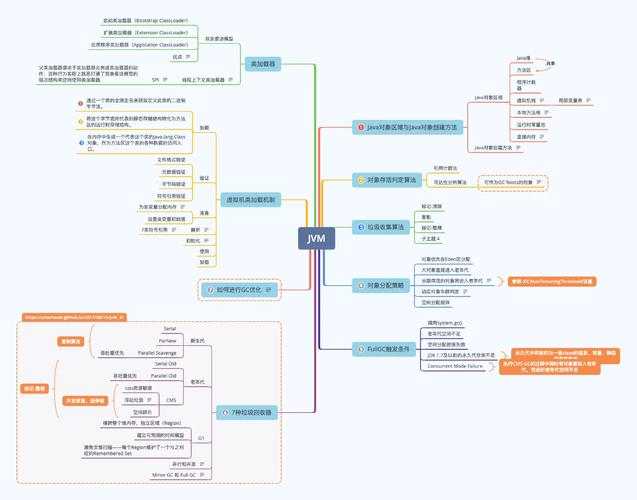
一、Java大数据结构概述
Hadoop:Hadoop生态体系包含HDFS(分布式文件体系)、MapReduce(分布式核算结构)和YARN(资源办理体系)等,是大数据范畴的柱石。
Spark:Spark Core是分布式核算结构,支撑批处理和流处理,功能优于Hadoop MapReduce。
Flink:Flink是流处理结构,支撑有界和无界数据流处理,具有高功能和低推迟的特色。
Hive:Hive是依据Hadoop的数据仓库东西,能够将结构化数据映射为表,并支撑SQL查询。
HBase:HBase是一个分布式、可扩展的NoSQL数据库,适用于存储非结构化和半结构化数据。
Kafka:Kafka是一个分布式流处理渠道,用于构建实时数据管道和流运用程序。
Storm:Storm是一个分布式实时核算体系,用于处理大规划数据流。
二、Java大数据结构技能选型
在挑选Java大数据结构时,需求考虑以下要素:
数据处理需求:依据实践事务需求,挑选合适的结构。例如,假如需求处理批处理数据,能够挑选Hadoop或Spark;假如需求处理实时数据流,能够挑选Flink或Storm。
功能要求:依据数据处理量、速度和推迟等功能指标,挑选功能最优的结构。
易用性:考虑结构的学习曲线、文档和社区支撑等要素,挑选易于运用的结构。
生态体系:挑选具有丰厚生态体系的结构,以便更好地与其他东西和库集成。
三、Java大数据结构运用实践
电商引荐体系:使用Spark进行用户行为剖析,完成个性化引荐。
金融风控体系:使用Hadoop和Hive进行海量买卖数据存储和剖析,完成危险预警。
交际网络剖析:使用Flink进行实时数据流处理,剖析用户联系和传达途径。
物联网数据收集:使用Kafka进行数据收集和传输,完成设备监控和办理。
Java大数据结构在处理和剖析大规划数据方面具有广泛的运用远景。经过合理的技能选型和实践运用,能够充分发挥这些结构的优势,为各行业供给高效、安稳的数据处了解决方案。本文对Java大数据结构进行了概述,并讨论了技能选型与运用实践,期望对读者有所协助。
本站所有图片均来自互联网,一切版权均归源网站或源作者所有。
如果侵犯了你的权益请来信告知我们删除。邮箱:[email protected]
猜你喜欢
-
银行大数据是什么意思,什么是银行大数据?



银行大数据一般指的是银行在日常运营过程中堆集的巨大而杂乱的数据调集。这些数据包含但不限于客户的个人信息、买卖记载、账户信息、信誉前史、商场趋势等。银行使用这些数据,经过大数据剖析技能,能够更深化地了解客户需求、优化服务流程、前进危险控制才能、增强商场竞赛力等。大数据剖析在银行中的使用十分广泛,例如:...。
2025-01-29数据库 -
玩脱了手游数据库,玩脱了手游数据库,我的游戏体会大打扣头!



1.玩脱了数据库的根本介绍:玩脱了手游数据库是一个专门为《FIFA足球国际》推出的球员数据库体系,玩家可以经过该体系查询和比照球员数据,进行阵型模仿和数据查看。2.数据更新与反应:数据库会定时更新,例如TOTS活动期间的数据更新,玩家可以前往相关中文数据库进行查看和比照。...。
2025-01-29数据库 -
装备办理数据库,深化解析装备办理数据库(CMDB)在IT运维中的重要性
装备办理数据库(ConfigurationManagementDatabase,简称CMDB)是一个存储和办理企业IT财物信息的数据库,它记载了IT基础设施...
2025-01-29数据库 -
数据库查询重复数据,办法与技巧



为了查询数据库中的重复数据,咱们需求先确认以下几点:1.数据库类型:你运用的是哪种数据库(如MySQL、PostgreSQL、SQLite、Oracle等)。2.表结构:需求查询的表结构,特别是哪些列或许会包括重复数据。3.查询条件:你需求依据哪些列来辨认重复数据。因为你并未供给具体的信息,我...。
2025-01-29数据库 -
linux检查mysql日志,Linux体系下检查MySQL日志的具体攻略



在Linux体系中,检查MySQL日志文件一般能够经过以下过程进行:1.确认日志文件的方位:MySQL的日志文件一般坐落MySQL的数据目录下。这个目录的方位或许会依据你的MySQL装置办法而有所不同。默许状况下,这个目录或许是`/var/lib/mysql/`。日志文件的称号一般...。
2025-01-29数据库