python解析html文件, 假定HTML内容存储在html_content变量中html_content = Example Page Welcome to My Website This is a paragraph.
时间:2025-01-09阅读数:7
当然能够。要解析HTML文件,咱们一般运用Python中的`BeautifulSoup`库。`BeautifulSoup`是一个用于解析HTML和XML文档的库,它供给了一个简略的接口来处理HTML和XML文档。
以下是一个运用`BeautifulSoup`解析HTML文件的示例代码:
```pythonfrom bs4 import BeautifulSoup
假定HTML内容存储在html_content变量中html_content = Example Page Welcome to My Website This is a paragraph.

Item 1 Item 2 Item 3
运用BeautifulSoup解析HTMLsoup = BeautifulSoup
获取标题title = soup.title.string
获取一切阶段paragraphs = soup.find_all
获取一切列表项list_items = soup.find_all
输出成果printprintqwe2printqwe2```
这段代码首要界说了一个HTML字符串`html_content`,然后运用`BeautifulSoup`解析这个字符串。之后,咱们获取了标题、一切阶段和一切列表项,并将它们打印出来。
假如你有一个实践的HTML文件,你需求首要读取这个文件的内容,然后才干运用`BeautifulSoup`进行解析。这里是怎么读取一个名为`example.html`的HTML文件并解析它的内容:
```pythonfrom bs4 import BeautifulSoup
读取HTML文件with open as file: html_content = file.read
运用BeautifulSoup解析HTMLsoup = BeautifulSoup
...之后的代码与上面相同```
请保证你现已装置了`BeautifulSoup`库,假如没有,你能够运用`pip install beautifulsoup4`来装置它。
Python解析HTML文件:从入门到实践
HTML(HyperText Markup Language)是构建网页的根底,而Python作为一种功能强大的编程言语,在处理HTML文件方面有着广泛的运用。经过Python解析HTML文件,咱们能够提取信息、自动化网页内容处理等。本文将具体介绍怎么运用Python解析HTML文件,从基本概念到实践运用。
- ``:界说整个HTML文档。
- ``:包括文档的元数据,如标题、款式等。
- ``:包括文档的主体内容。
- ``:界说阶段。
- ``:界说超链接。
- ``:界说一个区域。
HTML特点

- `href`:界说超链接的方针地址。
- `class`:界说元素的CSS类。
- `id`:界说元素的仅有标识符。
解析HTML文件
BeautifulSoup库
BeautifulSoup是一个用于解析HTML和XML文档的Python库,它供给了简略易用的API来查找、遍历和修正文档树。以下是运用BeautifulSoup解析HTML文件的过程:
1. 装置BeautifulSoup库:
```python
pip install beautifulsoup4
```
2. 导入BeautifulSoup库:
```python
from bs4 import BeautifulSoup
```
3. 读取HTML文件:
```python
with open('example.html', 'r', encoding='utf-8') as file:
soup = BeautifulSoup(file, 'html.parser')
```
4. 查找元素:
```python
paragraphs = soup.find_all('p')
for paragraph in paragraphs:
print(paragraph.text)
```
lxml库
lxml是一个功能强大的Python库,用于处理XML和HTML文档。以下是运用lxml解析HTML文件的过程:
1. 装置lxml库:
```python
pip install lxml
```
2. 导入lxml库:
```python
from lxml import etree
```
3. 读取HTML文件:
```python
tree = etree.parse('example.html')
```
4. 查找元素:
```python
paragraphs = tree.xpath('//p')
for paragraph in paragraphs:
print(paragraph.text)
```
实践运用

提取网页信息
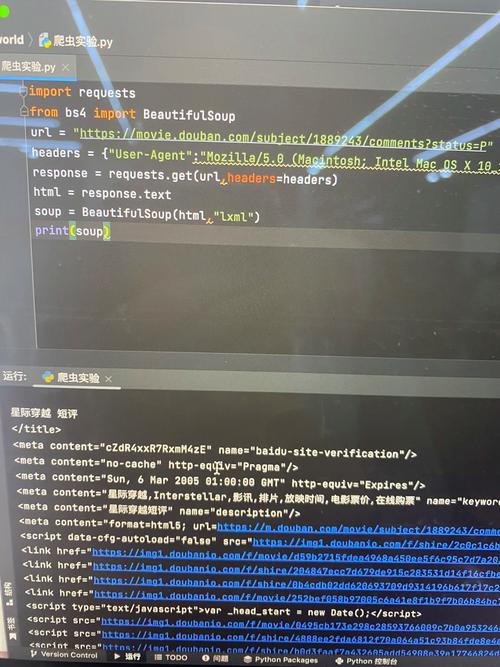
运用Python解析HTML文件,咱们能够提取网页中的各种信息,如:
- 文章标题
- 文章内容
- 图片链接
- 超链接
自动化网页内容处理
Python解析HTML文件还能够用于自动化网页内容处理,如:
- 网页爬虫
- 数据发掘
- 网络爬虫
本站所有图片均来自互联网,一切版权均归源网站或源作者所有。
如果侵犯了你的权益请来信告知我们删除。邮箱:[email protected]
猜你喜欢
-
html特殊符号代码,html特殊符号代码大全
HTML特殊符号代码,一般用于在网页中刺进一些无法直接经过键盘输入的字符,如版权符号?、商标符号?、欧元符号€",metadata:{}}}qwe2,st...
2025-01-21前端开发 -
h5和html5的差异



H5一般是指HTML5,但它们之间有一些纤细的差异。HTML5(HyperTextMarkupLanguage5)是HTML的最新版别,它是一种用于创立网页的标准符号言语。HTML5引入了许多新的特性,如新的元素、特点和API,这些特性使得网页开发愈加高效和灵敏。HTML5的首要意图是进步网页...。
2025-01-21前端开发 -
html开发东西有哪些,HTML5 开发东西概述



HTML开发东西多种多样,从简略的文本编辑器到功用强壮的集成开发环境(IDE),以下是几种常用的HTML开发东西:1.文本编辑器:Notepad:一款免费开源的文本和源代码编辑器,支撑多种编程言语。SublimeText:一个轻量级的文本编辑器,支撑多种编程言语和插件。...。
2025-01-21前端开发 -

css让文字笔直居中, 运用line-height特点完成笔直居中
要让文字在CSS中笔直居中,您能够运用多种办法,具体取决于您的布局需求。以下是几种常见的办法:1.运用Flexbox:Flexbox是一种现代的布局办法...
2025-01-21前端开发 -
css表格距离, 表格距离概述



CSS中调整表格距离能够经过设置`borderspacing`特点来完成。这个特点界说了表格中单元格之间的距离。假如表格的`bordercollapse`特点被设置为`separate`(这是默许值),则`borderspacing`特点收效。例如,假如你想设置一个表格的单元格之间的水平缓笔直距离各...。
2025-01-21前端开发