etree.html
时间:2025-01-11阅读数:12
`etree.html` 是一个字符串,它代表了一个 HTML 文档。这个字符串能够被用来创立一个 `ElementTree` 目标,该目标能够被用来解析和操作 HTML 文档。
例如,以下是怎么运用 `etree.html` 来解析 HTML 文档并提取其间的
```pythonimport xml.etree.ElementTree as ET
HTML 文档字符串html_doc = 我的网页 欢迎来到我的网页 这是一个示例 HTML 文档。
运用 etree.html 解析 HTML 文档tree = ET.fromstring
获取标题title = tree.find.textprint```
输出成果将是:
```标题: 我的网页```
在这个比如中,咱们首要界说了一个 HTML 文档字符串 `html_doc`。咱们运用 `ET.fromstring` 办法来解析这个字符串,并创立了一个 `ElementTree` 目标 `tree`。咱们运用 `tree.find` 办法来查找标题元素,并提取其文本内容。
`etree.html` 能够用来处理各种 HTML 文档,包含杂乱的文档。它供给了丰厚的 API 来操作 XML 和 HTML 文档,包含查找元素、修正元素、增加元素、删去元素等。
运用lxml库的etree.HTML()办法解析HTML文档
在处理HTML文档时,Python开发者通常会运用lxml库中的etree模块。etree模块供给了强壮的XML和HTML解析功用,使得开发者能够轻松地解析、查询和修正XML和HTML文档。本文将具体介绍lxml库中的etree.HTML()办法,并展现其在实践运用中的运用办法。
etree.HTML()办法简介
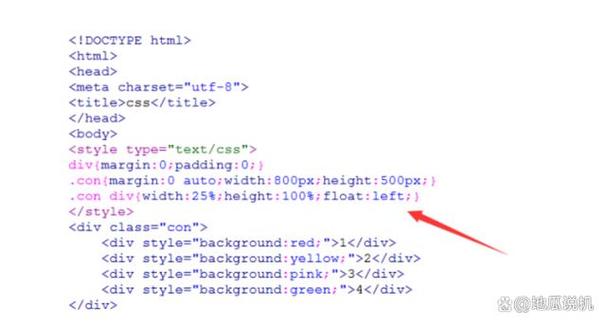
etree.HTML()是lxml库中etree模块的一个办法,用于将字符串格局的HTML文档解析成Element目标。Element目标是lxml库中用于表明XML和HTML文档的根本单元,它包含了文档的结构信息。
1. 解析HTML文档

运用etree.HTML()办法能够将字符串格局的HTML文档解析成Element目标。以下是一个简略的示例:
```python
from lxml import etree
html_text = '''
示例页面
欢迎来到我的博客
这是一个示例阶段。
html = etree.HTML(html_text)
print(html.tag) 输出:html
2. 运用Element目标
- `.xpath()`:依据XPath表达式查询元素。
- `.find()`:查找第一个匹配的元素。
- `.findall()`:查找一切匹配的元素。
- `.getparent()`:获取当时元素的父元素。
- `.getchildren()`:获取当时元素的子元素。
以下是一个运用Element目标查询HTML文档的示例:
```python
查询标题
title = html.xpath('//title/text()')[0]
print(title) 输出:示例页面
查询一切阶段
paragraphs = html.xpath('//p')
for paragraph in paragraphs:
print(paragraph.text) 输出:这是一个示例阶段。
etree.tostring()办法
除了解析HTML文档外,etree模块还供给了etree.tostring()办法,用于将Element目标转化成字符串格局的HTML文档。
1. 转化Element目标
运用etree.tostring()办法能够将Element目标转化成字符串格局的HTML文档。以下是一个示例:
```python
from lxml import etree
html = etree.HTML(html_text)
new_html = etree.tostring(html, pretty_print=True).decode()
print(new_html)
在上面的示例中,咱们首要解析了一个HTML文档,然后运用etree.tostring()办法将其转化成字符串格局的HTML文档,并打印出来。
2. pretty_print参数
etree.tostring()办法有一个可选的pretty_print参数,用于操控输出格局。当pretty_print=True时,输出格局将愈加漂亮,便于阅览。
本文介绍了lxml库中的etree.HTML()办法,并展现了其在实践运用中的运用办法。经过运用etree.HTML()办法,咱们能够轻松地将字符串格局的HTML文档解析成Element目标,并对其进行查询、修正和操作。此外,etree.tostring()办法还能够将Element目标转化成字符串格局的HTML文档,便利咱们进行输出和存储。
```html
etree.html办法详解
运用lxml库的etree.HTML()办法解析HTML文档
在处理HTML文档时,Python开发者通常会运用lxml库中的etree模块。etree模块供给了强壮的XML和HTML解析功用,使得开发者能够轻松地解析、查询和修正XML和HTML文档。本文将具体介绍lxml库中的etree.HTML()办法,并展现其在实践运用中的运用办法。
etree.HTML()办法简介
etree.HTML()是lxml库中etree模块的一个办法,用于将字符串格局的HTML文档解析成Element目标。Element目标是lxml库中用于表明XML和HTML文档的根本单元,它包含了文档的结构信息。
解析HTML文档
运用etree.HTML()办法能够将字符串格局的HTML文档解析成Element目标。以下是一个简略的示例:
etree.tostring()办法
除了解析HTML文档外,etree模块还供给了etree.tostring()办法,用于将Element目标转化成字符串
本站所有图片均来自互联网,一切版权均归源网站或源作者所有。
如果侵犯了你的权益请来信告知我们删除。邮箱:[email protected]
猜你喜欢
-
html特殊符号代码,html特殊符号代码大全
HTML特殊符号代码,一般用于在网页中刺进一些无法直接经过键盘输入的字符,如版权符号?、商标符号?、欧元符号€",metadata:{}}}qwe2,st...
2025-01-21前端开发 -
h5和html5的差异



H5一般是指HTML5,但它们之间有一些纤细的差异。HTML5(HyperTextMarkupLanguage5)是HTML的最新版别,它是一种用于创立网页的标准符号言语。HTML5引入了许多新的特性,如新的元素、特点和API,这些特性使得网页开发愈加高效和灵敏。HTML5的首要意图是进步网页...。
2025-01-21前端开发 -
html开发东西有哪些,HTML5 开发东西概述



HTML开发东西多种多样,从简略的文本编辑器到功用强壮的集成开发环境(IDE),以下是几种常用的HTML开发东西:1.文本编辑器:Notepad:一款免费开源的文本和源代码编辑器,支撑多种编程言语。SublimeText:一个轻量级的文本编辑器,支撑多种编程言语和插件。...。
2025-01-21前端开发 -

css让文字笔直居中, 运用line-height特点完成笔直居中
要让文字在CSS中笔直居中,您能够运用多种办法,具体取决于您的布局需求。以下是几种常见的办法:1.运用Flexbox:Flexbox是一种现代的布局办法...
2025-01-21前端开发 -
css表格距离, 表格距离概述



CSS中调整表格距离能够经过设置`borderspacing`特点来完成。这个特点界说了表格中单元格之间的距离。假如表格的`bordercollapse`特点被设置为`separate`(这是默许值),则`borderspacing`特点收效。例如,假如你想设置一个表格的单元格之间的水平缓笔直距离各...。
2025-01-21前端开发