大数据选用什么剖析处理的办法,大数据剖析处理办法概述
时间:2025-01-14阅读数:10
2. 确诊性剖析: 确诊性剖析用于确认数据中的问题和原因。例如,经过剖析出售数据来找出出售下降的原因。
3. 猜测性剖析: 猜测性剖析依据前史数据来猜测未来的趋势和方式。例如,经过剖析前史出售数据来猜测未来的出售趋势。
4. 规范性剖析: 规范性剖析供给决议计划支撑,协助确认最佳的举动计划。例如,经过剖析客户购买行为来拟定个性化的营销战略。
5. 数据发掘: 数据发掘是从很多数据中提取有价值的信息和常识的进程。它运用各种算法和技能,如分类、聚类、相关规矩发掘等。
6. 机器学习: 机器学习是一种使核算机能够从数据中学习并做出猜测或决议计划的技能。它包含监督学习、无监督学习、半监督学习和强化学习等。
7. 深度学习: 深度学习是机器学习的一个子范畴,它运用多层神经网络来学习数据的杂乱方式。深度学习在图像辨认、自然言语处理和语音辨认等范畴取得了明显效果。
8. 统计剖析: 统计剖析运用统计学办法来剖析数据,如回归剖析、方差剖析、假设检验等。这些办法协助了解数据之间的联系和影响。
9. 数据可视化: 数据可视化将数据以图表、图形等方式展现出来,使人们能够更直观地舆解数据。这有助于发现数据中的方式和趋势。
10. 实时剖析: 实时剖析是在数据生成的一起进行实时处理和剖析,以便快速做出决议计划。这关于需求实时呼应的运用场景十分重要。
11. 流处理: 流处理是对接连的数据流进行实时剖析,以便及时发现数据中的方式和反常。这关于处理很多实时数据的运用场景十分有用。
12. 散布式处理: 散布式处理将大数据散布在多个核算节点上进行处理,以进步处理速度和功率。这一般运用如Hadoop和Spark等散布式核算结构。
13. 内存核算: 内存核算是在核算机内存中存储和处理数据,以进步处理速度。这一般运用如Apache Flink和Apache Spark等内存核算结构。
14. 云核算: 云核算供给弹性的核算资源,能够依据需求动态调整资源分配,以便处理大数据。这一般运用如Amazon Web Services 、Microsoft Azure和Google Cloud Platform等云服务供给商。
15. 边际核算: 边际核算是在数据源邻近(如物联网设备)进行数据处理,以削减数据传输推迟和进步处理速度。这关于需求实时处理很多数据的物联网运用场景十分有用。
这些办法能够独自运用,也能够组合运用,以满意不同的剖析需求。挑选适宜的办法取决于数据的特性、剖析方针以及可用的技能资源。
大数据剖析处理办法概述
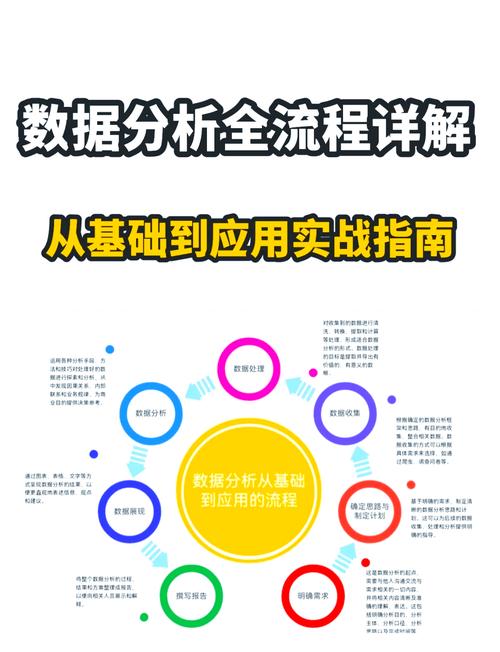
跟着信息技能的飞速发展,大数据已经成为各行各业重视的焦点。大数据剖析处理办法作为发掘数据价值的关键技能,关于企业决议计划、科学研究等范畴具有重要意义。本文将介绍几种常见的大数据剖析处理办法。
1. 数据预处理办法
数据预处理是大数据剖析处理的第一步,首要包含数据清洗、数据集成、数据转化和数据规约等。
1.1 数据清洗
数据清洗是指对原始数据进行清洗,去除过错、缺失、反常等不完整或不精确的数据。常用的数据清洗办法包含删去重复记录、添补缺失值、批改过错数据等。
1.2 数据集成

数据集成是指将来自不同数据源的数据进行整合,构成一个一致的数据集。数据集成办法包含数据兼并、数据映射和数据转化等。
1.3 数据转化

数据转化是指将原始数据转化为合适剖析处理的数据格式。常用的数据转化办法包含数据类型转化、数据规范化、数据标准化等。
1.4 数据规约
数据规约是指经过削减数据量来下降数据存储和处理本钱。常用的数据规约办法包含数据抽样、数据压缩、数据聚合等。
2. 数据剖析办法

数据剖析办法首要包含描绘性统计剖析、相关规矩发掘、聚类剖析、分类剖析、猜测剖析等。
2.1 描绘性统计剖析
描绘性统计剖析是对数据的基本特征进行描绘,如均值、标准差、最大值、最小值等。描绘性统计剖析有助于了解数据的散布状况。
2.2 相关规矩发掘
相关规矩发掘是指发现数据会集不同特色之间的相相联系。常用的相关规矩发掘算法包含Apriori算法、FP-growth算法等。
2.3 聚类剖析
聚类剖析是指将相似的数据目标归为一类,构成多个类别。常用的聚类算法包含K-means算法、层次聚类算法等。
2.4 分类剖析
分类剖析是指依据已知的数据对不知道数据进行分类。常用的分类算法包含决议计划树、支撑向量机、神经网络等。
2.5 猜测剖析
猜测剖析是指依据前史数据对未来数据进行猜测。常用的猜测剖析办法包含时刻序列剖析、回归剖析等。
3. 大数据剖析东西与技能

大数据剖析东西与技能首要包含Hadoop、Spark、Flink、Hive、Pig等。
3.1 Hadoop
Hadoop是一个开源的大数据处理结构,首要用于散布式存储和核算。Hadoop的中心组件包含HDFS(散布式文件体系)和MapReduce(散布式核算结构)。
3.2 Spark
Spark是一个开源的大数据处理结构,具有高性能、易用性等特色。Spark的中心组件包含Spark Core、Spark SQL、Spark Streaming等。
3.3 Flink
Flink是一个开源的大数据处理结构,首要用于实时数据处理。Flink的中心组件包含Flink Core、Flink SQL、Flink Table等。
3.4 Hive
Hive是一个依据Hadoop的数据仓库东西,首要用于数据剖析和查询。Hive的中心组件包含HiveQL(相似SQL的查询言语)和HiveServer2(Hive的HTTP服务器)。
3.5 Pig

Pig是一个依据Hadoop的数据处理东西,首要用于数据转化和加载。Pig的中心组件包含Pig Latin(相似SQL的脚本言语)和PigStorage(数据存储和加载东西)。
大数据剖析处理办法在各个范畴都发挥着重要作用。本文介绍了数据预处理、数据剖析办法、大数据剖析东西与技能等方面的内容,旨在协助读者更好地了解大数据剖析处理办法。
本站所有图片均来自互联网,一切版权均归源网站或源作者所有。
如果侵犯了你的权益请来信告知我们删除。邮箱:[email protected]
猜你喜欢
-
银行大数据是什么意思,什么是银行大数据?



银行大数据一般指的是银行在日常运营过程中堆集的巨大而杂乱的数据调集。这些数据包含但不限于客户的个人信息、买卖记载、账户信息、信誉前史、商场趋势等。银行使用这些数据,经过大数据剖析技能,能够更深化地了解客户需求、优化服务流程、前进危险控制才能、增强商场竞赛力等。大数据剖析在银行中的使用十分广泛,例如:...。
2025-01-29数据库 -
玩脱了手游数据库,玩脱了手游数据库,我的游戏体会大打扣头!



1.玩脱了数据库的根本介绍:玩脱了手游数据库是一个专门为《FIFA足球国际》推出的球员数据库体系,玩家可以经过该体系查询和比照球员数据,进行阵型模仿和数据查看。2.数据更新与反应:数据库会定时更新,例如TOTS活动期间的数据更新,玩家可以前往相关中文数据库进行查看和比照。...。
2025-01-29数据库 -
装备办理数据库,深化解析装备办理数据库(CMDB)在IT运维中的重要性
装备办理数据库(ConfigurationManagementDatabase,简称CMDB)是一个存储和办理企业IT财物信息的数据库,它记载了IT基础设施...
2025-01-29数据库 -
数据库查询重复数据,办法与技巧



为了查询数据库中的重复数据,咱们需求先确认以下几点:1.数据库类型:你运用的是哪种数据库(如MySQL、PostgreSQL、SQLite、Oracle等)。2.表结构:需求查询的表结构,特别是哪些列或许会包括重复数据。3.查询条件:你需求依据哪些列来辨认重复数据。因为你并未供给具体的信息,我...。
2025-01-29数据库 -
linux检查mysql日志,Linux体系下检查MySQL日志的具体攻略



在Linux体系中,检查MySQL日志文件一般能够经过以下过程进行:1.确认日志文件的方位:MySQL的日志文件一般坐落MySQL的数据目录下。这个目录的方位或许会依据你的MySQL装置办法而有所不同。默许状况下,这个目录或许是`/var/lib/mysql/`。日志文件的称号一般...。
2025-01-29数据库