大数据搜集东西,大数据搜集东西概述
时间:2025-01-15阅读数:8
1. Flume:Apache Flume 是一个分布式、牢靠且可用的服务,用于高效地搜集、聚合和移动很多日志数据。它支撑多种数据源和数据目的地,而且具有容错和可扩展性。
2. Logstash:Logstash 是一个强壮的数据处理管道,能够一起从多个来历搜集数据,转化数据,然后将数据发送到您指定的“存储库”中,如 Elasticsearch。
3. Kafka:Apache Kafka 是一个分布式流处理渠道,它能够高效地处理很多的实时数据流。Kafka 能够作为数据搜集东西,从各种来历搜集数据,并将数据存储在 Kafka 集群中,以便进行进一步的处理和剖析。
4. Sqoop:Apache Sqoop 是一个用于在 Apache Hadoop 和结构化数据存储(如联系数据库)之间传输很多数据的东西。它能够将数据从联系数据库导入到 Hadoop 生态体系中的各种存储体系中,也能够将数据从 Hadoop 生态体系导出到联系数据库中。
5. NiFi:Apache NiFi 是一个易于运用、功用强壮的数据集成和数据处理渠道。它支撑从各种来历搜集数据,并供给丰厚的数据处理功用,如数据转化、数据路由和数据监控等。
6. Talend Open Studio:Talend Open Studio 是一个开源的数据集成东西,它供给了丰厚的数据搜集、转化和集成功用。它支撑多种数据源和数据目的地,而且具有强壮的数据映射和转化功用。
7. Apache Nutch:Apache Nutch 是一个开源的网络爬虫东西,它能够用于从互联网上搜集很多网页数据。Nutch 支撑多种爬虫战略和数据提取技能,而且能够与其他大数据处理东西集成。
8. Apache Tika:Apache Tika 是一个内容剖析东西,它能够用于从各种文件格局中提取元数据和内容。Tika 支撑多种文件格局,而且能够与其他大数据处理东西集成。
9. Octoparse:Octoparse 是一个强壮的网页数据搜集东西,它能够主动从各种网站搜集数据。Octoparse 支撑多种数据搜集形式和数据提取技能,而且具有易用性和可定制性。
10. BeautifulSoup:BeautifulSoup 是一个用于解析 HTML 和 XML 文档的 Python 库。它能够用于从网页中提取数据,而且与其他 Python 库(如 requests)集成。
这些东西各有特色,适用于不同的数据搜集场景。挑选适宜的东西取决于您的详细需求和数据源的类型。
大数据搜集东西概述
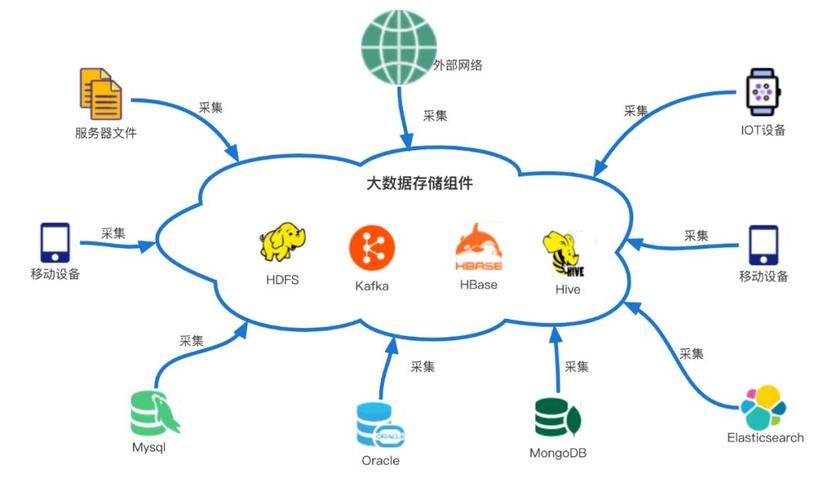
大数据搜集东西的概念

大数据搜集东西是指用于从各种数据源中抓取和搜集数据的软件或服务。这些数据源包含但不限于联系型数据库、非联系型数据库、日志文件、传感器数据、交际媒体等。大数据搜集东西的首要功用是高效、精确地获取数据,为后续的数据处理和剖析供给根底。
大数据搜集东西的分类
依据使用领域和功用,大数据搜集东西能够分为以下几类:
联系型数据库搜集东西:如Sqoop、Odi等,首要用于从联系型数据库中搜集数据。
非联系型数据库搜集东西:如MongoDB、Cassandra等,首要用于从非联系型数据库中搜集数据。
日志文件搜集东西:如Flume、Logstash等,首要用于从日志文件中搜集数据。
传感器数据搜集东西:如IoT设备搜集东西、气候数据搜集东西等,首要用于从传感器设备中搜集数据。
交际媒体搜集东西:如Twitter API、Facebook API等,首要用于从交际媒体渠道中搜集数据。
常用大数据搜集东西介绍
1. Sqoop
Sqoop是一款开源的数据搜集东西,专门规划用于在Hadoop生态体系和联系型数据库之间高效传输批量数据。其首要功用包含数据搬迁、数据搜集和成果导出。Sqoop底层依据MapReduce程序模板完成,支撑多种数据源和方针存储体系。
2. Flume
Flume是一款分布式、牢靠、可扩展的日志搜集体系,首要用于从各种数据源(如日志文件、网络流、命令行东西等)搜集数据,并将其传输到会集的存储体系(如HDFS、HBase等)。Flume具有高牢靠性和可扩展性,适用于大规模数据搜集场景。
3. Logstash
Logstash是一款开源的数据搜集和传输东西,首要用于从各种数据源(如日志文件、数据库、音讯行列等)搜集数据,并将其转化、过滤、路由到方针存储体系(如Elasticsearch、Hadoop等)。Logstash具有强壮的数据处理才能和灵敏的数据路由功用。
4. Apache Kafka
Apache Kafka是一款分布式流处理渠道,首要用于构建实时数据流使用。Kafka具有高吞吐量、可扩展性和容错性,适用于大规模数据搜集和实时数据处理场景。
挑选适宜的大数据搜集东西
数据源类型:了解数据源的类型,挑选适宜的数据搜集东西。
方针存储体系:了解方针存储体系的特色,挑选兼容性好的数据搜集东西。
数据处理才能:依据数据处理需求,挑选具有强壮数据处理才能的搜集东西。
可扩展性和牢靠性:挑选具有高可扩展性和牢靠性的搜集东西,保证数据搜集进程的安稳运转。
大数据搜集东西在数据搜集进程中发挥着重要作用。了解大数据搜集东西的概念、分类和常用东西,有助于咱们更好地挑选适宜的数据搜集东西,为大数据处理和剖析供给有力支撑。在往后的工作中,咱们将持续重视大数据搜集东西的开展,为读者供给更多有价值的信息。
本站所有图片均来自互联网,一切版权均归源网站或源作者所有。
如果侵犯了你的权益请来信告知我们删除。邮箱:[email protected]
猜你喜欢
-
银行大数据是什么意思,什么是银行大数据?



银行大数据一般指的是银行在日常运营过程中堆集的巨大而杂乱的数据调集。这些数据包含但不限于客户的个人信息、买卖记载、账户信息、信誉前史、商场趋势等。银行使用这些数据,经过大数据剖析技能,能够更深化地了解客户需求、优化服务流程、前进危险控制才能、增强商场竞赛力等。大数据剖析在银行中的使用十分广泛,例如:...。
2025-01-29数据库 -
玩脱了手游数据库,玩脱了手游数据库,我的游戏体会大打扣头!



1.玩脱了数据库的根本介绍:玩脱了手游数据库是一个专门为《FIFA足球国际》推出的球员数据库体系,玩家可以经过该体系查询和比照球员数据,进行阵型模仿和数据查看。2.数据更新与反应:数据库会定时更新,例如TOTS活动期间的数据更新,玩家可以前往相关中文数据库进行查看和比照。...。
2025-01-29数据库 -
装备办理数据库,深化解析装备办理数据库(CMDB)在IT运维中的重要性
装备办理数据库(ConfigurationManagementDatabase,简称CMDB)是一个存储和办理企业IT财物信息的数据库,它记载了IT基础设施...
2025-01-29数据库 -
数据库查询重复数据,办法与技巧



为了查询数据库中的重复数据,咱们需求先确认以下几点:1.数据库类型:你运用的是哪种数据库(如MySQL、PostgreSQL、SQLite、Oracle等)。2.表结构:需求查询的表结构,特别是哪些列或许会包括重复数据。3.查询条件:你需求依据哪些列来辨认重复数据。因为你并未供给具体的信息,我...。
2025-01-29数据库 -
linux检查mysql日志,Linux体系下检查MySQL日志的具体攻略



在Linux体系中,检查MySQL日志文件一般能够经过以下过程进行:1.确认日志文件的方位:MySQL的日志文件一般坐落MySQL的数据目录下。这个目录的方位或许会依据你的MySQL装置办法而有所不同。默许状况下,这个目录或许是`/var/lib/mysql/`。日志文件的称号一般...。
2025-01-29数据库