大数据剖析算法及模型,大数据剖析算法及模型概述
时间:2025-01-24阅读数:2
大数据剖析算法及模型是大数据范畴中至关重要的组成部分,它们用于从很多数据中提取有价值的信息和常识。以下是几种常见的大数据剖析算法和模型:
1. 聚类算法(Clustering Algorithms): Kmeans:将数据点分组为K个簇,每个簇的中心点是数据点的均匀值。 层次聚类(Hierarchical Clustering):构建一个树状结构,表明数据点之间的类似性。 DBSCAN(DensityBased Spatial Clustering of Applications with Noise):依据密度的聚类算法,能够辨认出形状不规矩的簇。
2. 分类算法(Classification Algorithms): 决议计划树(Decision Trees):经过一系列的规矩对数据进行分类。 随机森林(Random Forest):由多个决议计划树组成的集成学习方法,能够进步分类的准确性和泛化才能。 支撑向量机(SVM):经过寻觅一个超平面来最大化不同类别之间的间隔,用于分类和回归使命。
3. 相关规矩发掘(Association Rule Mining): Apriori算法:用于发现频频项集和相关规矩,常用于购物篮剖析。 FPgrowth算法:一种高效的数据发掘算法,用于发现频频项集和相关规矩。
4. 时刻序列剖析(Time Series Analysis): ARIMA(自回归积分滑动均匀模型):用于猜测时刻序列数据的未来值。 LSTM(长短期回忆网络):一种特别的循环神经网络,用于处理和猜测时刻序列数据。
5. 文本发掘(Text Mining): TFIDF(词频逆文档频率):用于评价一个词在文档会集的重要性。 LDA(隐含狄利克雷散布):用于主题建模,将文档调集分解为潜在的主题。
6. 引荐体系(Recommendation Systems): 协同过滤(Collaborative Filtering):依据用户的前史行为来引荐物品或服务。 内容引荐(ContentBased Filtering):依据用户的前史行为和物品的特征来引荐。
7. 降维(Dimensionality Reduction): 主成分剖析(PCA):经过线性变换将数据投影到较低维度的空间,保存大部分方差。 tSNE(t散布式随机邻域嵌入):一种非线性降维技能,用于可视化高维数据。
8. 神经网络(Neural Networks): 卷积神经网络(CNN):用于图像辨认和分类。 循环神经网络(RNN):用于处理序列数据,如自然语言处理和时刻序列剖析。 生成对立网络(GAN):由生成器和判别器组成,用于生成新的数据样本。
这些算法和模型能够依据详细的使用场景和需求进行挑选和组合,以完成高效的大数据剖析。
大数据剖析算法及模型概述
跟着信息技能的飞速发展,大数据已经成为当今社会的重要资源。大数据剖析作为一门交叉学科,交融了统计学、核算机科学、信息科学等多个范畴,旨在从海量数据中发掘出有价值的信息和常识。大数据剖析算法及模型是大数据剖析的中心,本文将介绍几种常见的大数据剖析算法及模型。
1. 相关规矩发掘算法
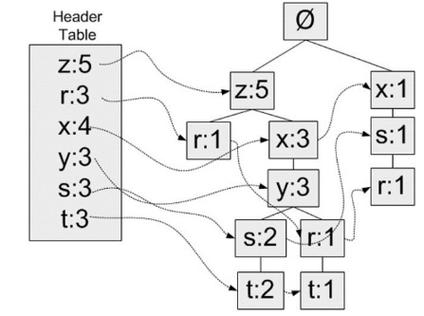
相关规矩发掘算法是大数据剖析中的一种重要算法,首要用于发现数据项之间的相相关系。常见的相关规矩发掘算法有Apriori算法和FP-growth算法。
Apriori算法经过迭代的方法,逐渐生成频频项集,并从中发掘出相关规矩。该算法的缺陷是核算复杂度较高,尤其是在处理大规模数据集时。
FP-growth算法经过构建频频形式树(FP-tree)来存储频频项集,然后下降算法的核算复杂度。FP-growth算法在处理大规模数据集时具有较好的功能。
2. 聚类剖析算法
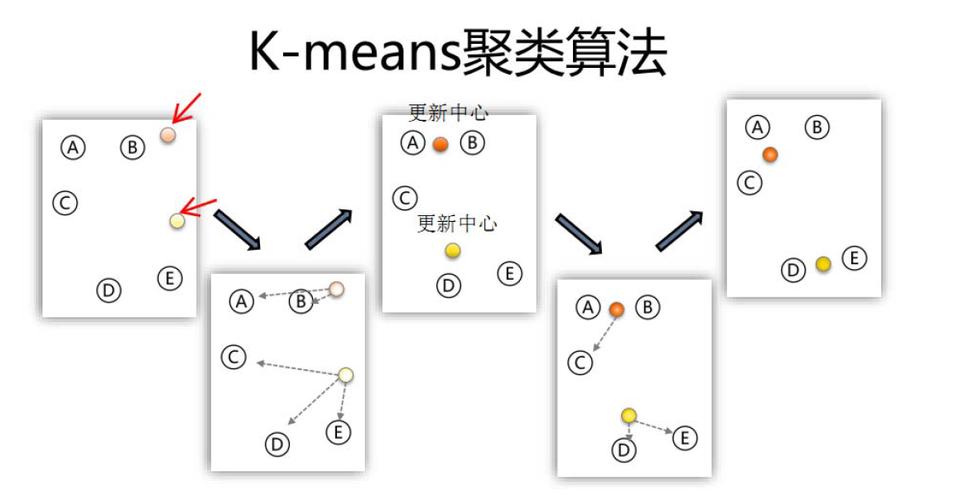
聚类剖析算法用于将数据集划分为若干个簇,使得同一簇内的数据点具有较高的类似度,而不同簇之间的数据点具有较低的类似度。常见的聚类剖析算法有K-means算法和DBSCAN算法。
K-means算法经过迭代的方法,逐渐优化簇的中心点,使得每个数据点与其地点簇的中心点的间隔最小。K-means算法在处理大规模数据集时,需求预先指定簇的数量。
DBSCAN算法是一种依据密度的聚类算法,它经过核算数据点之间的间隔,将数据点划分为簇。DBSCAN算法不需求预先指定簇的数量,且对噪声数据具有较强的鲁棒性。
3. 决议计划树算法
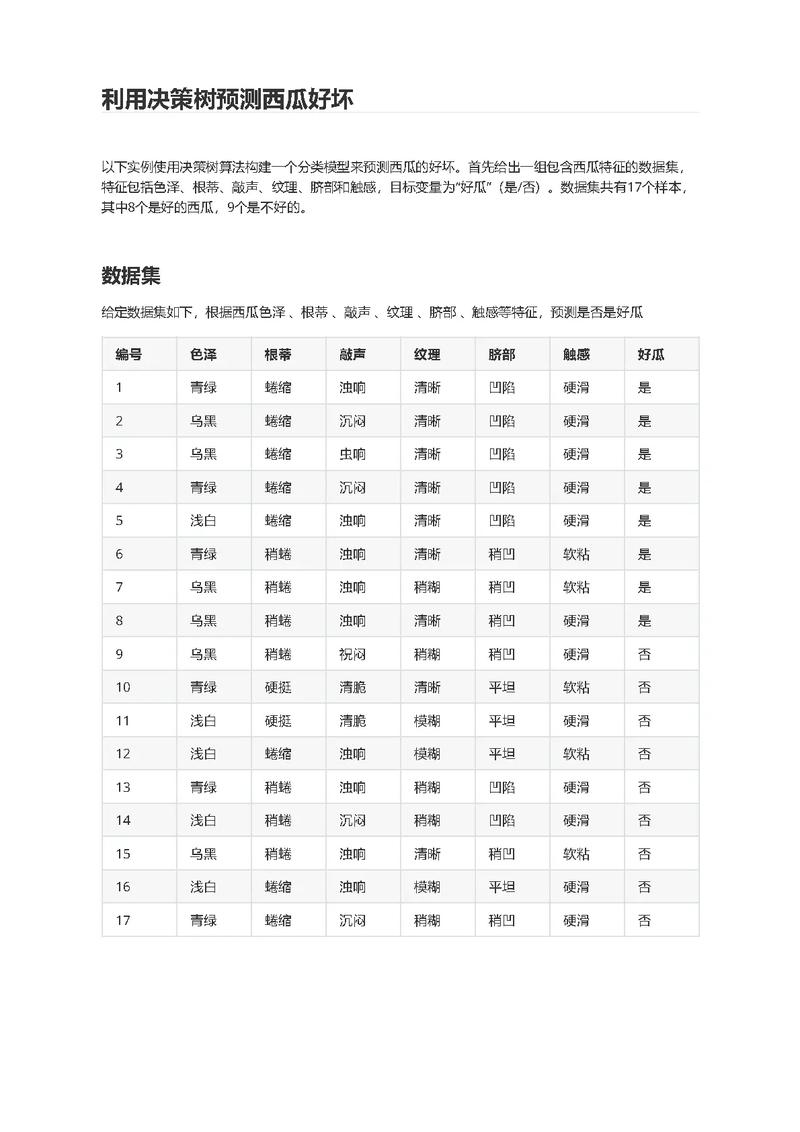
决议计划树算法是一种常用的分类和猜测算法,它经过构建一棵树来表明数据项之间的决议计划进程。常见的决议计划树算法有C4.5算法和CART算法。
C4.5算法是一种依据信息增益的决议计划树算法,它经过核算每个特征的信息增益来挑选最优特征。C4.5算法在处理不平衡数据集时具有较好的功能。
CART算法是一种依据基尼指数的决议计划树算法,它经过核算每个特征对数据集的基尼指数来挑选最优特征。CART算法在处理大规模数据集时具有较好的功能。
4. 人工神经网络算法
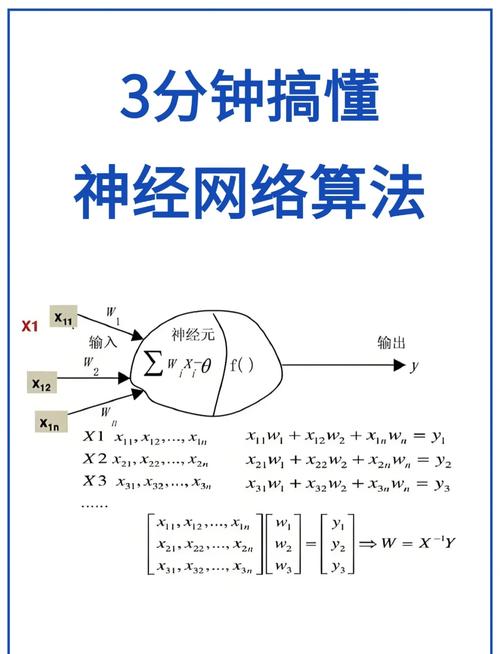
人工神经网络算法是一种模仿人脑神经元结构的核算模型,它经过学习数据中的特征和形式来猜测或分类数据。常见的人工神经网络算法有BP神经网络和CNN神经网络。
BP神经网络是一种依据差错反向传达算法的神经网络,它经过不断调整网络权值来优化模型。BP神经网络在处理非线性问题时具有较好的功能。
CNN神经网络是一种卷积神经网络,它经过卷积层、池化层和全衔接层来提取数据中的特征。CNN神经网络在图像辨认、语音辨认等范畴具有较好的功能。
大数据剖析算法及模型是大数据剖析的中心,本文介绍了相关规矩发掘算法、聚类剖析算法、决议计划树算法和人工神经网络算法等常见的大数据剖析算法及模型。在实践使用中,应依据详细问题和数据特色挑选适宜的算法及模型,以进步大数据剖析的功率和准确性。
本站所有图片均来自互联网,一切版权均归源网站或源作者所有。
如果侵犯了你的权益请来信告知我们删除。邮箱:[email protected]
猜你喜欢
-
银行大数据是什么意思,什么是银行大数据?



银行大数据一般指的是银行在日常运营过程中堆集的巨大而杂乱的数据调集。这些数据包含但不限于客户的个人信息、买卖记载、账户信息、信誉前史、商场趋势等。银行使用这些数据,经过大数据剖析技能,能够更深化地了解客户需求、优化服务流程、前进危险控制才能、增强商场竞赛力等。大数据剖析在银行中的使用十分广泛,例如:...。
2025-01-29数据库 -
玩脱了手游数据库,玩脱了手游数据库,我的游戏体会大打扣头!



1.玩脱了数据库的根本介绍:玩脱了手游数据库是一个专门为《FIFA足球国际》推出的球员数据库体系,玩家可以经过该体系查询和比照球员数据,进行阵型模仿和数据查看。2.数据更新与反应:数据库会定时更新,例如TOTS活动期间的数据更新,玩家可以前往相关中文数据库进行查看和比照。...。
2025-01-29数据库 -
装备办理数据库,深化解析装备办理数据库(CMDB)在IT运维中的重要性
装备办理数据库(ConfigurationManagementDatabase,简称CMDB)是一个存储和办理企业IT财物信息的数据库,它记载了IT基础设施...
2025-01-29数据库 -
数据库查询重复数据,办法与技巧



为了查询数据库中的重复数据,咱们需求先确认以下几点:1.数据库类型:你运用的是哪种数据库(如MySQL、PostgreSQL、SQLite、Oracle等)。2.表结构:需求查询的表结构,特别是哪些列或许会包括重复数据。3.查询条件:你需求依据哪些列来辨认重复数据。因为你并未供给具体的信息,我...。
2025-01-29数据库 -
linux检查mysql日志,Linux体系下检查MySQL日志的具体攻略



在Linux体系中,检查MySQL日志文件一般能够经过以下过程进行:1.确认日志文件的方位:MySQL的日志文件一般坐落MySQL的数据目录下。这个目录的方位或许会依据你的MySQL装置办法而有所不同。默许状况下,这个目录或许是`/var/lib/mysql/`。日志文件的称号一般...。
2025-01-29数据库